Oracle DBA - RAC Interview
Oracle Real Application Cluster
Q1 What are the background process that exists in 11gr2
and functionality?
|
Process Name
|
Functionality
|
|
Crsd
|
•The CRS daemon (crsd) manages cluster resources based on
configuration information that is stored in Oracle Cluster Registry (OCR) for
each resource. This includes start, stop, monitor, and failover operations.
The crsd process generates events when the status of a resource changes.
|
|
Cssd
|
•Cluster Synchronization Service (CSS): Manages the cluster
configuration by controlling which nodes are members of the cluster and by
notifying members when a node joins or leaves the cluster. If you are using
certified third-party clusterware, then CSS processes interfaces with your
clusterware to manage node membership information. CSS has three separate
processes: the CSS daemon (ocssd), the CSS Agent (cssdagent), and the CSS
Monitor (cssdmonitor). The cssdagent process monitors the cluster and provides
input/output fencing. This service formerly was provided by Oracle Process
Monitor daemon (oprocd), also known as OraFenceService on Windows. A
cssdagent failure results in Oracle Clusterware restarting the node.
|
|
Diskmon
|
•Disk Monitor daemon (diskmon): Monitors and performs
input/output fencing for Oracle Exadata Storage Server. As Exadata storage
can be added to any Oracle RAC node at any point in time, the diskmon daemon
is always started when ocssd is started.
|
|
Evmd
|
•Event Manager (EVM): Is a background process that publishes
Oracle Clusterware events
|
|
Mdnsd
|
•Multicast domain name service (mDNS): Allows DNS requests. The
mDNS process is a background process on Linux and UNIX, and a service on
Windows.
|
|
Gnsd
|
•Oracle Grid Naming Service (GNS): Is a gateway between the
cluster mDNS and external DNS servers. The GNS process performs name
resolution within the cluster.
|
|
Ons
|
•Oracle Notification Service (ONS): Is a publish-and-subscribe
service for communicating Fast Application Notification (FAN) events
|
|
Oraagent
|
•oraagent: Extends clusterware to support Oracle-specific
requirements and complex resources. It runs server callout scripts when FAN
events occur. This process was known as RACG in Oracle Clusterware 11g
Release 1 (11.1).
|
|
orarootagent
|
•Oracle root agent (orarootagent): Is a specialized oraagent
process that helps CRSD manage resources owned by root, such as the network,
and the Grid virtual IP address
|
|
Oclskd
|
•Cluster kill daemon (oclskd): Handles instance/node evictions
requests that have been escalated to CSS
|
|
Gipcd
|
•Grid IPC daemon (gipcd): Is a helper daemon for the
communications infrastructure
|
|
Ctssd
|
•Cluster time synchronisation daemon(ctssd) to manage the time
syncrhonization between nodes, rather depending on NTP
|
Q2 Under which user or owner the
process will start?
|
Component
|
Name of the Process
|
Owner
|
|
Oracle High Availability Service
|
Ohasd
|
init, root
|
|
Cluster Ready Service (CRS)
|
Cluster Ready Services
|
root
|
|
Cluster Synchronization Service (CSS)
|
ocssd,cssd monitor, cssdagent
|
grid owner
|
|
Event Manager (EVM)
|
evmd, evmlogger
|
grid owner
|
|
Cluster Time Synchronization Service (CTSS)
|
Octssd
|
root
|
|
Oracle Notification Service (ONS)
|
ons, eons
|
grid owner
|
|
Oracle Agent
|
Oragent
|
grid owner
|
|
Oracle Root Agent
|
Orarootagent
|
root
|
Q3 Components of RAC ?
1 Shared Disk System
2 Oracle Clusterware
3 Clusterware interconnects
4 Oracle Kernel Components
Q4 what is the use of
OCR? How do you find out what OCR
backups are available?
The
purpose of the Oracle Cluster Registry (OCR) is to hold cluster and database
configuration information for RAC and Cluster Ready Services (CRS) such as the
cluster node list, and cluster database instance to node mapping, and CRS
application resource profiles.
The ocrconfig -show backup can be run to find
out the automatic and manually run backups.
If your OCR is corrupted what options
do have to resolve this?
You can use either the logical or the physical
OCR backup copy to restore the Repository.
ocrconfig
-restore
How to relocate the OCR
disk(/dev/raw/raw6) to new
location(/dev/raw/raw9).
ocrconfig -replace current_file_name
-replacement new_file_name
How to repair OCR
ocrconfig -repair -add file_name | -delete file_name | -replace
current_file_name -replacement new_file_name
How to find location of OCR file when
CRS is down?
If you
need to find the location of OCR (Oracle Cluster Registry) but your CRS is
down.
When
the CRS is down:
Look
into “ocr.loc” file, location of this file changes depending on the OS:
On
Linux: /etc/oracle/ocr.loc
On
Solaris: /var/opt/oracle/ocr.loc
How Automatic Backup of OCR is done and which process
takes the backup?
Automatic backup of OCR
is done by CRSD process and every 3 hours. Default location is
CRS_home/cdata/cluster_name. But we can change default location of this backup
of OCR. We can check default location using following command.
$ocrconfig -showbackup
We can change this
default location of physical OCR copies using following command.
$ocrconfig –backuploc
How you take backup of
ocr/vd in rac 10g and 11g.-----
for ocr(ocrconfig
–manualbackup)..
and for voting disk
(dd if=/dev/raw/raw3
of=/u03/crs_backup/votebackup/VotingDiskBackup.dmp bs=4k)
For more info on OCR link: https://docs.oracle.com/cd/E11882_01/rac.112/e41959/ocrsyntax.htm#CWADD92028
Q5 . How you'll check
services in RAC.
1.
crs_stat –t to
check all services status.
2.
By checking the
status of individual nodes and all the necessary applications, we can see that
the VIP, GSD, Listener and the ONS daemons are alive.
srvctl status nodeapps -n vm01
srvctl status nodeapps -n vm02
3.
status of the
ASM on both nodes.
srvctl status asm -n vm01
srvctl status asm -n vm02
4. database status
srvctl status database -d
5. Cluster Status.
crsctl check crs (both Side)
6. select instance_name, host_name, archiver, thread#, status
from gv$instance;
7. select name, path, header_status, total_mb free_mb, trunc(bytes_read/1024/1024) read_mb, trunc(bytes_written/1024/1024) write_mb
from v$asm_disk;
Q6 What is Voting disk?
Voting
disk manages cluster
membership by way of a health check and arbitrates cluster ownership among the
instances in case of network failures. RAC uses the voting disk to determine
which instances are members of a cluster. The voting disk must reside on shared
disk. For high availability, Oracle recommends that you have multiple voting
disks. The Oracle Clusterware enables multiple voting disks.
And status for the voting disk can be
check with below mentioned command
crsctl
query css votedisk
Q7 Why we required to maintain odd number of voting disks?
Odd
number of disk are to avoid split brain, When Nodes in cluster can't talk to
each other they run to lock the Voting disk and whoever lock the more disk will
survive, if disk number are even there are chances that node might lock 50% of
disk (2 out of 4) then how to decide which node to evict.
whereas when number is odd, one will be higher than other and each for cluster
to evict the node with less number
Q8 How to check the status of Voting disk?
crsctl query css votedisk
Q 9 How to relocate the
voting disk(/dev/raw/raw5) to new location(/dev/raw/raw8).
crsctl replace votedisk
/dev/raw/raw8/
Q 10 What is the Oracle Recommendation for backing up voting disk?
Oracle recommends us to use the dd
command to backup the voting disk with a minimum block size of 4KB.
Q 11 How do you restore a voting disk?
To restore the backup of your voting
disk, issue the dd or ocopy command for Linux and UNIX systems or ocopy for Windows
systems respectively.
On Linux or UNIX systems:
dd if=backup_file_name
of=voting_disk_name
On Windows systems, use the ocopy
command:
ocopy backup_file_name voting_disk_name
where,
backup_file_name is the name of the
voting disk backup file
voting_disk_name is the name of the
active voting disk
Q 12 How can we add and
remove multiple voting disks?
If we have multiple voting disks, then
we can remove the voting disks and add them back into our environment using the
following commands, where path is the complete path of the location where the
voting disk resides:
crsctl delete css votedisk path
crsctl add css votedisk path
Q13 How do you backup voting disk ?
#dd if=voting_disk_name of=backup_file_name
Q14 How to public,virtual
and private IP's in RAC?
In Oracle RAC clusters, we see three
types of IP addresses:
Public IP: The public IP address is for the server. This is the same as any server IP address, a
unique address with exists in /etc/hosts.
Private IP: Oracle RACrequires
"private IP" addresses to manage the CRS, the clusterware heartbeat
process and the cache fusion layer.
Virtual IP: Oracle uses a Virtual IP (VIP) for database
access. The VIP must be on the same
subnet as the public IP address. The VIP
is used for RAC failover (TAF).
Q15 What is cache fusion and cache coherency?
Cache
Fusion
In a RAC
environment, it is the combining of data blocks, which are shipped across the
interconnect from remote database caches (SGA) to the local node, in order to
fulfill the requirements for a transaction (DML, Query of Data Dictionary).
https://mgrvinod.wordpress.com/2011/03/22/cache-fusion/
Cache Coherency
Whether the database is a single-instance stand-alone
system or a multi-instance RAC system, maintaining data consistency is a
fundamental requirement. If data blocks are already available in the local
buffer cache, then they are immediately available for user processes. And, if
they are available in another instance within the cluster, they will be
transferred into the local buffer cache.Maintaining the iconsistency of data
blocks in the buffer caches of multiple instances is called cache coherency
Q16 Why we need more then two eathernet card.
Each node must have at least two network interface cards (NIC), or network adapters. One adapter is for the public network interface and the other adapter is for the private network interface (the interconnect). Install additional network adapters on a node if that node meets either of the following conditions:
Does not have at least two network adapters
Has two network interface cards but is using network attached storage (NAS). You should have a separate network adapter for NAS.
Has two network cards, but you want to use redundant interconnects
In previous releases, to make use of redundant networks for the interconnect, bonding, trunking, teaming, or similar technology was required. Oracle Grid Infrastructure for a cluster and Oracle RAC can now make use of redundant network interconnects, without the use of other network technology, to enhance optimal communication in the cluster. This functionality is available starting with Oracle Database 11g Release 2 (11.2.0.2).
Redundant Interconnect Usage enables load-balancing and high availability across multiple (up to 4) private networks (also known as interconnects).
In the event of Node Eviction which file is
updated by CRS?
Voting Disk file will be updated.
Each node in the cluster is “pinged”
every second
Nodes must respond in css_misscount time
(defaults to 30 secs.)
–
Reducing the css_misscount time is generally not supported
Network heartbeat failures will lead to
node evictions
CSSD-log:
[date / time] [CSSD][1111902528]
clssnmPollingThread: node mynodename (5) at 75% heartbeat fatal,
removal in 6.7 sec
Disk Heartbeat:-
Each node in the cluster “pings” (r/w)
the Voting Disk(s) every second
Nodes must receive a response in (long /
short) diskTimeout time
–
IF I/O errors indicate clear accessibility problems timeout is irrelevant
Disk heartbeat failures will lead to
node evictions
CSSD-log: …
[CSSD] [1115699552] >TRACE: clssnmReadDskHeartbeat:node(2) is down.
rcfg(1) wrtcnt(1) LATS(63436584) Disk lastSeqNo(1)
Now, we know with above possibilities
(network, disk heartbeat failures can lead to node eviction, but sometime when
the server/occsd/resource request also makes the node get evicted which are
extreme cases)
Why nodes should be evicted?
Evicting (fencing) nodes is a preventive
measure (it’s a good thing)!
Nodes are evicted to prevent
consequences of a split brain:
– Shared data must not be written by independently operating nodes .
– The easiest way to prevent this is to forcibly remove a node from the
cluster.
How to check software version of cluster.
crsctl query crs softwareversion
[hostname]
How to Find OCR Master Node in RAC?
1. The default OCR master is always the
first node that’s started in the cluster.
2. When OCR master (crsd.bin process) stops or
restarts for whatever reason, the crsd.bin on surviving node with lowest node number
will become new OCR master.
The following method can be used to find
OCR master:
1. By searching crsd.l* on all nodes:
grep “OCR MASTER”
$GRID_HOME/log/$HOST/crsd/crsd.l*
*In my case i have exported ORACLE_HOME
to /u01/app/11.2.0/grid
so it is like
grep “OCR MASTER”
$ORACLE_HOME/log/$HOST/crsd/crsd.l*
If
there’s output, the last line will show who OCR master is. If the cluster has
been up and running on all nodes for a long while, as crsd.log keeps rotating to crsd.l01,
and crsd.l01 to crsd.l02 till crsd.l10, there’s a chance the above grep
command will not return anything. If that’s the case, see Step 2.
2. By locating automatic
OCR backup:
OCR automatic backup is
done by OCR master every 4 hours. In above example, latest automatic backup was
done around 2013/12/06 15:21:04 by racnode1 which means racnode1 was and
may still be OCR master since 2013/12/06 15:21:04 .
select MASTER_NODE from v$ges_resource;
and another way is command (#olsnodes) whichever node comes first is master
node and another way is to check occsd.log for the master node number.
Why OLR is introduced in 11g? what is the benefit?
In Oracle Clusterware 11g Release 2 an
additional component related to the OCR called the Oracle Local Registry (OLR)
is installed on each node in the cluster. The OLR is a local registry for node
specific resources. THe OLR is not shared by other nodes in the cluster. It is
installed and configured when Oracle clusterware is installed.
Purpose of OLR in11g
————–
It is the very first file that is
accessed to startup clusterware when OCR
is stored on ASM. OCR should be accessible to find out the resources which need
to be started on a node. If OCR is on ASM, it can’t be read until ASM (which
itself is a resource for the node and this information is stored in OCR) is up.
To resolve this problem, information about the resources which need to be
started on a node is stored in an operating system file which is called Oracle Local Registry or
OLR. Since OLR is a file an operating system file, it can be accessed by
various processes on the node for read/write irrespective of the status of the clusterware
(up/down). Hence, when a node joins the
cluster, OLR on that node is read,
various resources ,including ASM are
started on the node . Once ASM is up ,
OCR is accessible and is used henceforth to manage all the clusterware
resources. If OLR is missing or corrupted, clusterware can’t be started on that
node!
Where is OLR located?
———————
The OLR file is located in the
grid_home/cdata/.olr . The location of OLR is stored in
/etc/oracle/olr.loc.and used by OHASD .
What does OLR contain?
———————-
The OLR stores
–
version of clusterware
- clusterware configuration
- configuration of various resources
which need to be started on the node
Mention the components of Oracle clusterware?
Oracle clusterware is made up of components like voting disk
and Oracle Cluster Registry(OCR).
Oracle clusterware is used to manage
high-availability operations in a cluster.
Anything that Oracle Clusterware manages is known as a CRS resource.
Some examples of CRSresources are database,an instance,a
service,a listener,a VIP address,
an application process etc
What is SCAN in Oracle 11g R2 RAC?
Single client access name (SCAN) is
meant to facilitate single name for all Oracle clients to connect to the
cluster database, irrespective of number of nodes and node location. Until now,
we have to keep adding multiple address records in all clients tnsnames.ora,
when a new node gets added to or deleted from the cluster.
What is FAN?
Fast application Notification as it
abbreviates to FAN relates to the events related to instances,services and
nodes.This is a notification mechanism that Oracle RAc uses to notify other
processes about the configuration and service level information that includes
service status changes such as,UP or DOWN events.Applications can respond to
FAN events and take immediate action.
What is TAF?
TAF (Transparent Application Failover)
is a configuration that allows session fail-over between different nodes of a
RAC database cluster.
Transparent Application Failover (TAF).
If a communication link failure occurs after a connection is established, the
connection fails over to another active node. Any disrupted transactions are
rolled back, and session properties and server-side program variables are lost.
In some cases, if the statement executing at the time of the failover is a
Select statement, that statement may be automatically re-executed on the new
connection with the cursor positioned on the row on which it was positioned
prior to the failover.
After an Oracle RAC node crashes—usually
from a hardware failure—all new application transactions are automatically
rerouted to a specified backup node. The challenge in rerouting is to not lose
transactions that were "in flight" at the exact moment of the crash.
One of the requirements of continuous availability is the ability to restart
in-flight application transactions, allowing a failed node to resume processing
on another server without interruption. Oracle's answer to application failover
is a new Oracle Net mechanism dubbed Transparent Application Failover. TAF
allows the DBA to configure the type and method of failover for each Oracle Net
client.
TAF architecture offers the ability to
restart transactions at either the transaction (SELECT) or session level.
What is ONS?
Oracle Clusterware uses ONS to send
notifications about the state of the database instances to midtier
applications that use this information
for load-balancing and for fast failure detection.
ONS is a daemon process that
communicates with other ONS daemons on other nodes which inform
each other of the current state of the
database components on the database server.
What is CRS?
Cluster Ready Services (CRS) provides
overall management of the cluster activities. CRS requires two key files that
must be located in logical drives on the shared disks: one for a Voting Disk
and one for the Oracle Cluster Registry(OCR). So, these two files must be
readily available on shared disk before CRS installation.
In 2
node RAC, how many NIC’s are r using ?
2 network cards on each clusterware node
Network Card 1 (with IP address set 1) for
public network
Network Card 2 (with IP address set 2) for
private network (for inter node communication between rac nodes used by
clusterware and rac database)
What are Oracle Kernel Components (nothing but how does Oracle RAC
database differs than Normal single instance database in terms of Binaries and
process)
Basically Oracle kernel need to switched on
with RAC On option when you convert to RAC, that is the difference as it
facilitates few RAC bg process like LMON,LCK,LMD,LMS etc.
To turn on RAC
# link the oracle libraries
$ cd $ORACLE_HOME/rdbms/lib
$ make -f ins_rdbms.mk rac_on
# rebuild oracle
$ cd $ORACLE_HOME/bin
$ relink oracle
Oracle RAC is composed of two or more database
instances. They are composed of Memory structures and background processes same
as the single instance database.Oracle RAC instances use two processes
GES(Global Enqueue Service), GCS(Global Cache Service) that enable cache
fusion.Oracle RAC instances are composed of following background processes:
ACMS—Atomic Controlfile to Memory Service
(ACMS)
GTX0-j—Global Transaction Process
LMON—Global Enqueue Service Monitor
LMD—Global Enqueue Service Daemon
LMS—Global Cache Service Process
LCK0—Instance Enqueue Process
RMSn—Oracle RAC Management Processes (RMSn)
RSMN—Remote Slave Monitor
What is Clusterware?
Software that provides various interfaces and
services for a cluster. Typically, this includes capabilities that:
·
Allow the cluster to be managed as a whole
·
Protect the integrity of the cluster
·
Maintain a registry of resources across the cluster
·
Deal with changes to the cluster
·
Provide a common view of resources
|
Grid Naming Service (GNS)
|
Gnsd
|
Root
|
|
Grid Plug and Play (GPnP)
|
Gpnpd
|
grid owner
|
|
Multicast domain name service (mDNS)
|
Mdnsd
|
grid owner
|
what is
past image in RAC and
resource locater?
The
past image concept was introduced in the RAC version of Oracle 9i to maintain
data integrity. In an Oracle database, a typical data block is not written to
the disk immediately, even after it is dirtied. When the same dirty data block
is requested by another instance for write or read purposes, an image of the
block is created at the owning instance, and only that block is shipped to the
requesting instance. This backup image of the block is called the past image
(PI) and is kept in memory. In the event of failure, Oracle can reconstruct the
current version of the block by reading PIs. It is also possible to have more
than one past image in the memory depending on how many times the data block
was requested in the dirty stage.
A
past image copy of the data block is different from a CR block, which is needed
for reconstructing a read-consistent image. A CR version of a block represents
a consistent snapshot of the data at a point in time. It is constructed by
applying information from the undo/rollback segments. The PI image copy helps
the recovery process and aids in maintaining data integrity.
For
example, suppose user A of instance 1 has updated row 2 on block 5. Later, user
B of instance 2 intends to update row 6 on the same block 5. The GCS transfers
block 5 from instance A to instance B. At this point, the past image (PI) for
block 5 is created on instance A.
Resource coordination within
Real Application Clusters occurs at both an instance level and at a cluster
database level. Instance level resource coordination within Real Application
Clusters is referred to as local resource coordination.
Cluster level coordination is referred to as global resource
coordination.
The processes that manage local
resource coordination in a cluster database are identical to the local resource
coordination processes in single instance Oracle. This means that row and block
level access, space management, system change number (SCN) creation, and data
dictionary cache and library cache management are the same in Real Application
Clusters as in single instance Oracle. Global resource coordination, however,
is somewhat more complex as described later in this chapter.
The Contents of the Global Resource Directory
Each instance's portion of the
Global Resource Directory contains information about the current statuses of
all shared resources. Oracle also uses information in the Global Resource
Directory during instance failure recovery or cluster reconfigurations.
The types of shared resource
information in the Global Resource Directory include:
- Data block identifiers, such as a data
block addresses
- Locations of the most current versions of
data blocks if they have been read into buffer caches on multiple nodes in
the cluster
- The modes
in which data blocks are being held by instances: (N) Null, (S) Shared, or
(X) Exclusive
- The roles
in which data blocks are being held by each instance: local or global
Where are Oracle cluster log files located?
The following Oracle log files are helpful for resolving issues
with Oracle components:
Table: Oracle Clusterware log files
|
|
Log file location
|
Cluster Ready Services Daemon (crsd) Log Files
|
$CRS_HOME/log/hostname/crsd
|
Cluster Synchronization Services (CSS)
|
$CRS_HOME/log/hostname/cssd
|
Event Manager (EVM) information generated
by evmd
|
$CRS_HOME/log/hostname/evmd
|
|
|
$CRS_HOME/log/hostname/racg
$ORACLE_HOME/log/hostname/racg
|
Table: Oracle RAC 11g
Release 2 log files
|
|
Log file location
|
|
|
$GRID_HOME/log//alert.log
|
|
|
$GRID_HOME/log//diskmon
|
OCRDUMP, OCRCHECK, OCRCONFIG, CRSCTL
|
$GRID_HOME/log//client
|
Cluster Time Synchronization Service
|
$GRID_HOME/log//ctssd
|
Grid Interprocess Communication daemon
|
$GRID_HOME/log//gipcd
|
Oracle High Availability Services daemon
|
$GRID_HOME/log//ohasd
|
Cluster Ready Services daemon
|
$GRID_HOME/log//crsd
|
Grid Plug and Play daemon
|
$GRID_HOME/log//gpnpd
|
Mulitcast Domain Name Service daemon
|
$GRID_HOME/log//mdnsd
|
|
|
$GRID_HOME/log//evmd
|
RAC RACG (only used if pre-11.1 database is
installed)
|
$GRID_HOME/log//racg
|
Cluster Synchronization Service daemon
|
$GRID_HOME/log//cssd
|
|
|
$GRID_HOME/log//srvm
|
|
|
$GRID_HOME/log//agent/ohasd/\
oraagent_oracle11
|
HA Service Daemon CSS Agent
|
$GRID_HOME/log//agent/ohasd/\
oracssdagent_root
|
HA Service Daemon ocssd Monitor Agent
|
$GRID_HOME/log//agent/ohasd/\
oracssdmonitor_root
|
HA Service Daemon Oracle Root Agent
|
$GRID_HOME/log//agent/\
ohasd/orarootagent_root
|
|
|
$GRID_HOME/log//agent/\
crsd/oraagent_oracle11
|
CRS Daemon Oracle Root Agent
|
$GRID_HOME/log/ agent/\
crsd/orarootagent_root
|
Grid Naming Service daemon
|
$GRID_HOME/log//gnsd
|
Table:
Oracle database log file
|
|
Log file location
|
|
|
$ORACLE_BASE/diag/rdbms/database_name/SID/
|
How does oracle RAC database connects to ASM Instance?
The database communicates with ASM instance using the ASMB
(umblicus process) process. Once the database obtains the necessary extents
from extent map, all database IO going forward is processed through by
the database processes, bypassing ASM. Thus we say ASM is not really in the IO
path. So, the question how do we make ASM go faster…..you don’t have to
What are the file types that ASM
support and keep in disk groups?
|
Control files
|
Flashback logs
|
Data Pump dump sets
|
|
Data files
|
DB SPFILE
|
Data Guard configuration
|
|
Temporary data files
|
RMAN backup sets
|
Change tracking bitmaps
|
|
Online redo logs
|
RMAN data file copies
|
OCR files
|
|
Archive logs
|
Transport data files
|
ASM SPFILE
|
50. awr report in rac
11gr2 new awr reports for Real Application
Clusters
Leave a reply
There are two new awr reports in 11gr2, which
will be helpful to dba’s in Real Application Clusters Environments (RAC).
awrgrpt.sql
This is a cluster wide awr report, so you can
see a lot of the information from all the nodes in the same section, and you can
also see aggregated statistics from all the instances at the same time (You can
see totals, averages and standard deviations).
awrgdrpt.sql
This is a cluster wide stats diff report (like
you had awrddrpt.sql in 11gr1), comparing the stats differences between two
different snapshot intervals, across all nodes in the cluster.
These are huge additions to the awr reports,
that enable understanding the database performance in real application clusters
environments.
Q .How to Cluster Name ,public,virtual and
private IP's and PUBLIC / VIP Node name
in RAC?
As per defined IP Addresses in /etc/hosts,
Let’s find the same information using various commands available from GRID and
OS.
Let’s verify the same if Grid (cluster) picked
up the correct IP’s.
NODE-1
=========
mgracsolsrv64bit1:/export/home/grid: cat
/etc/hosts
#
# Internet host table
#
::1
localhost
127.0.0.1
localhost
192.168.56.99
mgsrv-dns
mgsrv-dns.mgdom.com loghost
#PUBLIC
192.168.56.20
mgracsolsrv64bit1 mgracsolsrv64bit1.mgdom.com
192.168.56.21
mgracsolsrv64bit2 mgracsolsrv64bit2.mgdom.com
#PRIVATE
192.168.05.01
mgracsolsrv64bit1-priv mgracsolsrv64bit1-priv.mgdom.com
192.168.05.02
mgracsolsrv64bit2-priv mgracsolsrv64bit2-priv.mgdom.com
#VIRTUAL
192.168.56.30 mgracsolsrv64bit1-vip
mgracsolsrv64bit1-vip.mgdom.com
192.168.56.31 mgracsolsrv64bit2-vip mgracsolsrv64bit2-vip.mgdom.com
###########################################################################################################
1) To Find Cluster Name
###########################################################################################################
$ /u01/app/11.2.0.1/grid/bin/olsnodes -c
mgrac-cluster
###########################################################################################################
2) Find the PUBLIC and VIP Node name
###########################################################################################################
$ /u01/app/11.2.0.1/grid/bin/olsnodes -n -i
mgracsolsrv64bit1 1
mgracsolsrv64bit1-vip
mgracsolsrv64bit2 2
mgracsolsrv64bit2-vip
$ /u01/app/11.2.0.1/grid/bin/srvctl config
nodeapps -a
VIP exists.:mgracsolsrv64bit1
VIP exists.:
/mgracsolsrv64bit1-vip/192.168.56.30/255.255.255.0/e1000g0
VIP exists.:mgracsolsrv64bit2
VIP exists.:
/mgracsolsrv64bit2-vip/192.168.56.31/255.255.255.0/e1000g0
$ /u01/app/11.2.0.1/grid/bin/crsctl stat res
ora.mgracsolsrv64bit1.vip -p |egrep
‘^NAME|TYPE|USR_ORA_VIP|START_DEPENDENCIES|SCAN_NAME|VERSION’
NAME=ora.mgracsolsrv64bit1.vip
TYPE=ora.cluster_vip_net1.type
START_DEPENDENCIES=hard(ora.net1.network)
pullup(ora.net1.network)
USR_ORA_VIP=mgracsolsrv64bit1-vip
VERSION=11.2.0.1.0
###########################################################################################################
3) To find Private IP Details
###########################################################################################################
$ /u01/app/11.2.0.1/grid/bin/olsnodes -n -i -l
-p
mgracsolsrv64bit1 1
192.168.5.1
mgracsolsrv64bit1-vip =>
(Middle one is Private IP – 192.168.5.1)
The Oracle Interface Configuration Tool
(oifcfg) is used define and administer network interfaces such as the public
and private interfaces.
———————————————————————————————————————————————
Oracle only store network interface name and subnet
ID in OCR, not the netmask. Oifcfg command can be used for such change, oifcfg
commands only require to run on 1 of the cluster node, not all. When netmask is
changed, the associated subnet ID is also changed.
Interfaces used are : e1000g0
, e1000g1 , oifcfg would not show exact IP’s, instead it shows SubnetID in OCR.
Subnet Info in Oracle Clusterware – OCR – To
find out what’s in OCR:
Both public and private network information
are stored in OCR.
$ /u01/app/11.2.0.1/grid/bin/oifcfg getif
e1000g0
192.168.56.0 global public
e1000g1
192.168.0.0 global cluster_interconnect —-> Private Interface
Note:
The first column is the network adapter name
The second column is the subnet ID
The third column is always “global” and should
not be changed
The last column indicates whether it’s public
or cluster_interconnect(private) in Oracle Clusterware
To include the subnet mask, append the -n
option to the -p option:
Shows the available interfaces that you can
configure with setif.
The –p parameter displays the type of
interface which can be PRIVATE, PUBLIC or UNKNOWN.
The iflist command queries the operating
system to find which network interfaces are present on this node.
https://maleshg.wordpress.com/2013/11/03/identify-your-rac-newtork-details/
Is SRVCTL work on stand alone database.
No To add a database to the CRS stack, we need
to use the Server Control (SRVCTL) command. The below command will add a
database named “bc11gtst” to the stack and enable it to be restarted when the
server is restarted. Each of the options
used can be looked up with the help option ($GRID_HOME/bin/srvctl –h).
22: Which daemon in OC is responsible for
rebooting the node?
Cluster Ready Services (CRS)
$ ps -ef | grep crs | grep -v grep
root 25863 1 1 Oct27 ? 11:37:32
/opt/oracle/grid/product/11.2.0/bin/crsd.bin reboot
crsd.bin => The above process is
responsible for start, stop, monitor and failover of resource. It maintains OCR
and also restarts the resources when the failure occurs.
What
is a service?
A service is a logical grouping of
sessions performing similar kind of work. They enable you to group
database workloads and route work to the optimal instances that are assigned to
offer the service.It is recommended that all the users who connect using a
service have the same service-level requirements. We can use services to manage
workloads or a group of applications. For example , all on-line users can use
one service whereas batch users can use another service and reporting can use
yet another service.
Benefits
of services:
– Services make the work
more manageable, measurable, tunable and recoverable.
– Services provide an
abstraction layer and permit clients and middle tiers to access
required data from the database independent of where the instances reside.
– Dynamic: As the
load increases/reduces, the number of instances supporting a service can be
increased/decreased accordingly.
- High
availability : In
case an instance crashes, the services supported by it failover to another
surviving instance.
- Tuning and
Monitoring Aid
. Tracing can be enabled for
all the sessions who connect using a service: This can be used to identify the
culprit SQL statements issued by the users connected via a
service. . Performance statistics are collected and aggregated
by service: This can be used to find out the performance of all the sessions
belonging to a service.
. Two Performance thresholds can be
specified for a service: SERVICE_ELAPSED_TIME and SERVICE_CPU_TIME: The
AWR monitors the service time and CPU time and publishes alerts when the
performance esceeds the thresholds. In response to these alerts, you can change
the priority of a job, stop overloaded process , or relocate, expand, shrink ,
start or stop a service.
- Resource
Management Aid : We can
bind resource consumer groups to services. The users who connect using a
service will get the resources as per the allocation specified for the
respective consumer group in the active resource plan. For example, if OLTP and
BATCH services are defined to run on the same instance and our requirement is
as follows:
. During day time OLTP users
should get more resources whereas BATCH users should get less resources
. During night, BATCH
users should get more resources whereas OLTP users should get less resources
We can have
two consumer groups
: OLTP_GRP mapped to OLTP service and
BATCH_GRP
mapped to BATCH service
so that all users who connect using
OLTP service are assigned OLTP_GRP and all users who connect using BATCH
service are assigned BATCH_GRP .
We can have
two resource plans
:
. DAY_PLAN in which OLTP_GRP
is given more resources and BATCH_GRP is given less resources.
. NIGHT_PLAN in which
BATCH_GRP is given more resources and OLTP_GRP is given less resources.
- Job Control Aid : We can associate jobs with a
job class and job class can be mapped to service.
– If service is mapped to a
consumer group, the jobs will get the resources as per the allocation specified
for the respective consumer group in the active resource plan. If jobs of
a job class are taking more time than desired, we can change the consumer group
mapping of the respective service to one with more resources.
– If the instance running the jobs
of a job class crashes, the services on the crashed instance fail over to
another instance and all the jobs of the job class mapped to thst service
also failover along with it.
i.e.
Job1 —–+
Job2 ——|——– Jobclass1 —— Service1
Job3
——+
|
Consumer group
|
Resource Plan
– Using
Transparent Application Failover:
When a node crashes, all the services running on the instance hosted by that
node fail over to another instance. From now onwards, the users who try to
connect using failed over services will connect to the instances supporting
that service. But what happens to the sessions who were already connected using
that service at the time of crash? That is decided by the TAF (Transparent
application Failover) policy which can be defined for the service. We can have
3 types of TAF policies : Basic, Preconnect and None.
BASIC failover. In this approach, the application
connects to a backup node only after the primary connection fails. This
approach has low overhead, but the end user experiences a delay while the new
connection is created.
PRECONNECT
failover. In this approach, the application
simultaneously connects to both a primary and a backup node. This offers faster
failover, because a pre-spawned connection is ready to use. But the extra
connection adds everyday overhead by duplicating connections.
We can also
specify FAILOVER_TYPE for a service i.e. what kind of activity going
on in the connected sessions will be resumed after the failover . It can
be Select or Session.
SELECT
failover. With SELECT failover, Oracle Net
keeps track of all SELECT statements issued during the transaction, tracking
how many rows have been fetched back to the client for each cursor associated
with a SELECT statement. If the connection to the instance is lost, Oracle Net
establishes a connection to another Oracle RAC node and re-executes the SELECT
statements, repositioning the cursors so the client can continue fetching rows
as if nothing has happened. The SELECT failover approach is best for data
warehouse systems that perform complex and time-consuming transactions.
SESSION failover. When
the connection to an instance is lost, SESSION failover results only in the
establishment of a new connection to another Oracle RAC node; any work in
progress is lost. SESSION failover is ideal for online transaction processing
(OLTP) systems, where transactions are small.
The following types of transactions
do not automatically fail over and must be restarted by TAF:
- Transactional statements. Transactions involving
INSERT, UPDATE, or DELETE statements are not supported by TAF.
- ALTER SESSION
statements. ALTER SESSION and SQL*Plus SET statements do not fail
over.
- Transactions using temporary
segments in
the TEMP tablespace and global temporary tables do not fail over.
- PL/SQL package states. PL/SQL package states are
lost during failover.
– Connection Load balancing : If we have multiple instances
supporting a service, We can spread user connections across all those
instances. For each service, you can define the method that you want the
listener to use for load balancing by setting the connection load balancing goal,
CLB_GOAL. It can have two values : CLB_GOAL_LONG(default) and CLB_GOAL_SHORT.
Where’s the configuration
of services stored?
Data Dictionary (Bulk of service
configuration)
DBA_SERVICES
DBA_RSRC_GROUP_MAPPINGS
DBA_THRESHOLDS
DBA_SCHEDULER_JOB_CLASSES
TNSNAMES.ORA
Server-side
Entries for LOCAL_LISTENER and
REMOTE_LISTENER
Client-side (in tnsnames.ora)
CONNECT_DATA
Special entries for PRECONNECT
services
Resource profile in Cluster Registry
(OCR)
Resource
Start/stop script
Dependencies
Restart policy
Stringpairs
Instance list
Preferred/available instances
Enabled/disabled
TAF policy
Initialization Parameters
LOCAL_LISTENER
REMOTE_LISTENERS
DB_DOMAIN
DISPATCHERS
STATISTICS_LEVEL
Q . if asm has stopped working on a node, how
to bring that up?
I will
check the issue in the ASM instance alert log and whatever issue i get will
proceed to fix accordingly then again try to bring up the asm
Q. As
we know in RAC spfile resides on ASM, if spfile and controlfile has got lost,
how can
we
recover them?
Ans The
control file backup can be recovered from tape using RMAN
31: What is the use of policy-managed and administrator-managed databases
in services.
You can define services for both policy-managed and
administrator-managed databases.
· Policy-managed database: When you define services for a policy-managed database, you assign
the service to a server pool where the database is running. You can define the
service as either uniform (running on all instances in the server pool) or
singleton (running on only one instance in the server pool).
· Administrator-managed database: When you define a service for an administrator-managed database,
you define which instances normally support that service. These are known as
the PREFERRED instances. You can also define other instances to support a service
if the preferred instance fails. These are known as AVAILABLE
instances
·
26. In the event of Node Eviction
which file is updated by CRS.
·
·
. OCSSD : This process is
primary responsible for inter node health monitoring and instance endpoint
recovery. It runs as oracle user. It also provides basic cluster locking and
group services. It can run with or without vendor clusterware. The abnormal
termination or killing this process will reboot the node by init.cssd script.
If this script is killed then ocssd process will survive and node will keep
functioning. This script is called by /etc/inittab entry and when it tries to
respawn it and will try to start its own ocssd process. Since one ocssd process
is already running, this 2nd time script calling ocssd starting will fail and
2nd init.cssd script will reboot the node.
2. OPROCD : This process is known as checking hangcheck and drive freezes on
machine. On Linux, it is not available on 10.2.0.3 platform as this same
function is performed by linux hangcheck timer module. Starting from 10.2.0.4,
it will be started as part of clusterware startup and it runs as root. Killing
this process will reboot the node. If a machine is hang for long time, this
process needs to kill itself to avoid IO happening to disk so that rest of the
nodes can remaster the resources. This executable sets a signal handler and
sets the interval time bases on milliseconds parameter. It takes two parameters.
a. Timeout value –t : This is the length of time between executions. By default
it’s 1000.
b. Margin –m : This is the acceptable difference between dispatches. By
default, it’s 500.
When we set diagwait to 13, the margin becomes 13 -3 (reboottime seconds)= 10
seconds so value of m will be 10000.
There are two kinds of heartbeat mechanisms which are responsible for node
reboot and reconfiguration of remaining clusteware nodes.
a. Network heartbit : This indicates that node can participate in cluster
activities like group membership changes. When it’s missing for too long,
cluster membership will change as a result of reboot. This too long value is
determined by css miscount parameter value which is 30 seconds on most of
platforms but can be changed depending on network configuration of particular
environment. If at all it needs to be changed, it’s advisable to contact oracle
support and take their recommendations on this.
b. Disk heartbit : This disk heartbit means heartbits to voting disk file which
has the latest information about node members. Connectivity to a majority of
voting files must be maintained for a node to stay alive. Voting disk file uses
kill blocks to notify nodes they have been evicted and then remaining nodes can
go for reconfiguration and a node with least no will become master as per
Oracle algorithm generally. By default this value is 200 seconds which is css
disktimeout parameter. Again changing this parameter requires oracle support’s
recommendation. When node can no longer communicate through private
interconnect, other nodes can see its heartbits in voting file then it’s being
evicted by using voting disk kill block functionality.
Network split resolution : When network fails and nodes are not able to
communicate to each other then one node has to fail to maintain data integrity.
The surviving nodes should be an optimal subcluster of original cluster. Each
node writes its own vote to voting file and Reconfiguration manager component
reads these votes to calculate an optimal sub cluster. Nodes that are not to
survive are evicted via communication through network and disk.
Causes of reboot by clusterware processes
======================================
Now we will briefly discuss about causes of reboot by these processes and at
last, which files to review and upload to oracle support for further diagnosis.
Reboot by OCSSD.
============================
1. Network failure : 30 consecutive missed checkins will reboot a node where
heartbits are issues once per second. Some kind of messages in occsd.log like
heartbit fatal, eviction in xx seconds… Here there are two things.
a. If node eviction time in messages log file is less than missed checkins then
node eviction is likely not due to missed checkins.
b. If node eviction time in messages log file is greater than missed checkins
then node eviction is likely due to missed checkins.
2. Problems writing to voting disk file : some kind of hang in accessing voting
disk.
3. High CPU utilization : When CPU is highly utilized then css daemon doesn’t
get CPU on time to ping to voting disk and as a result, it cannot write to
voting disk file its own vote and node is going to be rebooted.
4. Disk subsystem is unresponsive due to storage issues.
5. Killing ocssd process.
6. An oracle bug.
Reboot by OPROCD.
============================
When a problem is detected by oprocd, it’ll reboot the node for following
reasons.
1. OS scheduler algorithm problem.
2. High CPU utilization due to which oprocd is not getting cpu to check hang
check issues at OS level.
3. An oracle bug.
Also just to share with you, at one of the client sites, lms processes were
running on low priority scheduling and lms were not getting cpu on time when
there’s cpu is high utilized so lms couldn’t communicate through clusterware
processes and node eviction got delayed and it was observed that oprocd
rebooted node which should not have happened as lms was responsible to run at
lower priority scheduling.
Determining cause of reboot by which process
==============================================
1. If there are below kind of messages in logfiles then it will be likely
reboot by ocssd process.
a. Reboot due to cluster integrity in syslog file or messages file.
b. Any error prior to reboot in ocssd.log file.
c. Missed checkins in syslog file and eviction time is prior to node reboot
time.
2. If there are below kind of messages in logfiles then it will be likely
reboot by oprocd process.
a. Resetting message in messages logfile on linux.
b. Any error in oprocd log matching with timestamp of reboot or prior to reboot
at /etc/oracle/oprocd directory.
3. If there are other messages like Ethernet issues or some kind of errors in
messages or syslog file then please check with sysadmins. On AIX, errpt –a
output gives lot of information about cause of reboot.
Log files collection while reboot of node
==============================================
Whenever node reboot occurs in clusterware environment, please review below
logfiles for getting reason of reboot and these files are necessary to upload
to oracle support for node eviction diagnosis.
a. CRS log files (For 10.2.0 and above 10.2.0 release)
=============================================
1. $ORACLE_CRS_HOME/log//crsd/crsd.log
2. $ORACLE_CRS_HOME/log//cssd/ocssd.log
3. $ORACLE_CRS_HOME/log//evmd/evmd.log
4. $ORACLE_CRS_HOME/log//alert.log
5. $ORACLE_CRS_HOME/log//client/cls*.log (not all files but only latest files
matching with timestamp of node reboot)
6. $ORACLE_CRS_HOME/log//racg/ (Please check files and directories matching
with timestamp of reboot and if found then copy otherwise not required)
7. The latest .oprocd.log file from /etc/oracle or /var/opt/oracle/oprocd
(Solaris)
Note: We can use $ORACLE_CRS_HOME/bin/diagcollection.pl to collect above files
but it doesn’t collect OPROCD logfiles, OS log files and OS watcher logfiles
and also it may take lot of time to run and consume resources so it’s better to
copy manually.
b. OS log files (This will get overwritten so we need to copy soon)
====================================================
1. /var/log/syslog
2. /var/adm/messages
3. errpt –a >error_.log (AIX only)
c. OS Watcher log files (This will get overwritten so we need to copy soon)
=======================================================
Please check in crontab where OSwatcher is installed. Go to that directory and
then archive folder and then collect files from all directory matching with
timestamp of node reboot.
1. OS_WATCHER_HOME/archive/oswtop
2. OS_WATCHER_HOME/archive/oswvmstat
3. OS_WATCHER_HOME/archive/oswmpstat
4. OS_WATCHER_HOME/archive/oswnetstat
5. OS_WATCHER_HOME/archive/oswiostat
6. OS_WATCHER_HOME/archive/oswps
7. OS_WATCHER_HOME/archive/oswprvtnet
5.What is GRD/GCS/GES.
Global Resource Directory
GES and GCS together maintain a
Global Resource Directory (GRD) to record the information about the resources
and the enqueues. GRD remains in the memory and is stored on all the instances.
Each instance manages a portion of the directory. This distributed nature is a
key point for fault tolerance of the RAC.
Global Resource Directory (GRD) is
the internal database that records and stores the current status of the data
blocks. Whenever a block is transferred out of a local cache to another
instance?s cache the GRD is updated. The following resources information is
available in GRD.
* Data Block Identifiers (DBA)
* Location of most current
version
* Modes of the data blocks: (N)Null,
(S)Shared, (X)Exclusive
* The Roles of the data blocks
(local or global) held by each instance
* Buffer caches on multiple nodes in
the cluster
GRD is akin to the previous version
of Lock Directory in the functionality perspective but has been expanded with
more components. It has accurate measure of inventory of resources and their
status and location.
GCS is the main controlling process
that implements Cache Fusion. GCS tracks the location and the status (mode and
role) of the data blocks, as well as the access privileges of various
instances. GCS is the mechanism which guarantees the data integrity by
employing global access levels. GCS maintains the block modes for data blocks
in the global role. It is also responsible for block transfers between the
instances. Upon a request from an Instance GCS organizes the block shipping and
appropriate lock mode conversions. The Global Cache Service is implemented by
various background processes, such as the Global Cache Service Processes (LMSn)
and Global Enqueue Service Daemon (LMD).
Global
Enqueue Service
The Global Enqueue Service (GES)
manages or tracks the status of all the Oracle enqueuing mechanism. This
involves all non Cache fusion intra-instance operations. GES performs
concurrency control on dictionary cache locks, library cache locks, and the
transactions. GES does this operation for resources that are accessed by more
than one instance.
GES/GCS
Areas
GES and GCS have the memory
structures associated with global resources. It is distributed across all
instances in a cluster. This area is located in the variable or shared pool
section of the SGA. As an example, below list shows the additions.
POOL
NAME
BYTES
------------ -------------------------- ----------
shared pool gcs
shadows
12143272
shared pool gcs
resources
17402792
shared pool ges enqueues
4079516
shared pool ges
resources
2624824
shared pool ges big msg
buffers 3839044
So far all the memory structures and
background processes have been surveyed. Now attention will be turned to the
physical database structures of the database which includes the data files,
redo log files and control files among other type of files.
8.How to start stop services /Node /DB.
How to stop
and start Oracle RAC services on two nodes RAC
To see status
[oracle@rac-node1 ~]$crs_stat -t
Name Type Target State Host
------------------------------------------------------------
ora....SM1.asm application ONLINE ONLINE dbsr...ode1
ora....E1.lsnr application ONLINE ONLINE dbsr...ode1
ora....de1.gsd application ONLINE ONLINE dbsr...ode1
ora....de1.ons application ONLINE ONLINE dbsr...ode1
ora....de1.vip application ONLINE ONLINE dbsr...ode1
ora....SM2.asm application ONLINE ONLINE dbsr...ode2
ora....E2.lsnr application ONLINE ONLINE dbsr...ode2
ora....de2.gsd application ONLINE ONLINE dbsr...ode2
ora....de2.ons application ONLINE ONLINE dbsr...ode2
ora....de2.vip application ONLINE ONLINE dbsr...ode2
ora.prod.db application ONLINE ONLINE dbsr...ode1
ora....b1.inst application ONLINE ONLINE dbsr...ode1
ora....b2.inst application ONLINE ONLINE dbsr...ode2
[oracle@rac-node1 ~]$
1: Stop database instance one by one
[oracle@rac-node1 ~]$ srvctl stop instance -i prod1 -d prod
[oracle@rac-node1 ~]$ srvctl stop instance -i prod2 -d prod
2: Stop ASM instance on each node one by one
[oracle@rac-node1 ~]$ srvctl stop asm -n rac-node1
[oracle@rac-node1 ~]$ srvctl stop asm -n rac-node2
3: Stop nodapplications one by one on each node
[oracle@rac-node1 ~]$ srvctl stop nodeapps -n rac-node1
[oracle@rac-node1 ~]$ srvctl stop nodeapps -n rac-node2
4: Check status again, to confirm that all services are
down
[oracle@rac-node1 ~]$ crs_stat -t
Name Type Target State Host
------------------------------------------------------------
ora....SM1.asm application OFFLINE OFFLINE
ora....E1.lsnr application OFFLINE OFFLINE
ora....de1.gsd application OFFLINE OFFLINE
ora....de1.ons application OFFLINE OFFLINE
ora....de1.vip application OFFLINE OFFLINE
ora....SM2.asm application OFFLINE OFFLINE
ora....E2.lsnr application OFFLINE OFFLINE
ora....de2.gsd application OFFLINE OFFLINE
ora....de2.ons application OFFLINE OFFLINE
ora....de2.vip application OFFLINE OFFLINE
ora.prod.db application OFFLINE OFFLINE
ora....b1.inst application OFFLINE OFFLINE
ora....b2.inst application OFFLINE OFFLINE
[oracle@rac-node1 ~]
To start services
1: Firs off all needs to start nodeapps on both nodes.
[oracle@rac-node1 ~]$ srvctl start nodeapps -n rac-node1
[oracle@rac-node1 ~]$ srvctl start nodeapps -n rac-node2
2: Start ASM on both nodes.
[oracle@rac-node1 ~]$ srvctl start asm -n rac-node1
[oracle@rac-node1 ~]$ srvctl start asm -n rac-node2
3: Start database instances
[oracle@rac-node1 ~]$ srvctl star instance -i prod1 -d prod
[oracle@rac-node1 ~]$ srvctl start instance -i prod2 -d prod
To confirm all service status
[oracle@rac-node1 ~]$crs_stat -t
Name Type Target State Host
------------------------------------------------------------
ora....SM1.asm application ONLINE ONLINE dbsr...ode1
ora....E1.lsnr application ONLINE ONLINE dbsr...ode1
ora....de1.gsd application ONLINE ONLINE dbsr...ode1
ora....de1.ons application ONLINE ONLINE dbsr...ode1
ora....de1.vip application ONLINE ONLINE dbsr...ode1
ora....SM2.asm application ONLINE ONLINE dbsr...ode2
ora....E2.lsnr application ONLINE ONLINE dbsr...ode2
ora....de2.gsd application ONLINE ONLINE dbsr...ode2
ora....de2.ons application ONLINE ONLINE dbsr...ode2
ora....de2.vip application ONLINE ONLINE dbsr...ode2
ora.prod.db application ONLINE ONLINE dbsr...ode1
ora....b1.inst application ONLINE ONLINE dbsr...ode1
ora....b2.inst application ONLINE ONLINE dbsr...ode2
[oracle@rac-node1 ~]$
17.Backup policy in RAC.
We are using one instance for export data pump
/ other once for RMAN in non business
hours
15.What happen if node is fail, Will updation
continue?
Transactional statements. Transactions
involving INSERT, UPDATE, or DELETE statements are not supported by TAF.
SELECT failover. With SELECT failover,
Oracle Net keeps track of all SELECT statements issued during the transaction,
tracking how many rows have been fetched back to the client for each cursor
associated with a SELECT statement. If the connection to the instance is lost,
Oracle Net establishes a connection to another Oracle RAC node and re-executes
the SELECT statements, repositioning the cursors so the client can continue
fetching rows as if nothing has happened. The SELECT failover approach is best
for data warehouse systems that perform complex and time-consuming
transactions.
13.What is the work of CRSD/CSSD
Cluster Synchronization Services (CSS): Manages the cluster configuration by controlling which nodes are
members of the cluster and by notifying members when a node joins or leaves the
cluster. If you are using certified third-party clusterware, then CSS processes
interface with your clusterware to manage node membership information.
The cssdagent process monitors the
cluster and provides I/O fencing. This service formerly was provided by Oracle
Process Monitor Daemon (oprocd), also known as OraFenceService on Windows. A cssdagent failure may result in Oracle Clusterware restarting the node.
Cluster
Ready Services (CRS): The primary program for managing high
availability operations in a cluster.The CRS daemon (crsd)
manages cluster resources based on the configuration information that is stored
in OCR for each resource. This includes start, stop, monitor, and failover
operations. The crsd process generates events when the status of a resource changes.
When you have Oracle RAC installed, the crsd process monitors
the Oracle database instance, listener, and so on, and automatically restarts
these components when a failure occurs
42. Can you add voting disk online?
Do you need voting disk backup?
Yes, as per documentation, if you have multiple voting
disk you can add online, but if you have only one voting disk , by that cluster
will be down as its lost you just need to start crs in exclusive mode and add
the votedisk using
43. You have lost OCR disk, what is
your next step?
The cluster stack will be down due to the fact that cssd is
unable to maintain the integrity, this is true in 10g, From 11gR2 onwards, the
crsd stack will be down, the hasd still up and running. You can add the ocr
back by restoring the automatic backup or import the manual backup,
37: What is scan listener, How to configure it
and where?
I hear that Oracle 11g release 2 has a new RAC feature
called SCAN (Single Client Access Name). How does SCAN replace TAF in a
RAC cluster? Should I use SCAN instead of manual load balancing?
Answer: According
to reliable sources on the web, SCAN provides a single domain name via DNS),
allowing and-users to address a RAC cluster as-if it were a single IP address.
SCAN works by replacing a hostname or IP list with virtual IP addresses
(VIP).
Because SCAN determines the actual node and listener which
accepts the connection, SCAN provides location independence for the
databases. A SCAN database connection does not require any details about
a particular node on instance. SCAN is part of the 11g release 2 movement
toward "RAC Virtualization". Virtualization is great for some
RAC shops, not so good for others.
Expert Note: SCAN is an automatic load balancing tool that uses a
relatively primitive least-recently-loaded algorithm. Most Fortune 50
mission critical RAC systems will not use an automated load balancer in favor
of intelligent RAC
load balancing., where you direct like-minded transactions to like-minded
nodes. This approach greatly reduces the load on the cache fusion payer
because less blocks must be sent across the RAC interconnect.
According to Oracle, there are two benefits for SCAN:
- Fast RAC failover: If a node fails, Oracle detects the loss of connection to
the VIP and redirects new connects to the surviving VIP's. This is
an alternative to the transparent
application failover. (TAF) for automatic
load balancing.
- Easier maintenance for Grid RAC systems: For Grid systems that gen-in and gen-out blade servers
frequently, SCAN offers easier change control for the RAC DBA. As
RAC nodes are added or deleted, the DBA does not have to change the
configuration files to reflect the current list of RAC node IP addresses
(or hostnames). In a nutshell, SCAN allows a single cluster alias
for all instances in the cluster.
Configuring RAC to use SCAN
The set-up for SCAN is implemented as follows:
STEP 1 - Add a new
DNS entry for SCAN (e.g. /etc/hosts). This will create a
single DNS domain name that resolves to all of the IP addresses in your RAC
cluster (one for each node). This will use a round-robin algorithm
root> cat /etc/hosts
myscan.mydomain.com IN A 122.22.22.22 IN A 122.22.22.23 IN
A 122.22.22.24
STEP 2 - Create a SCAN VIP for each IP address in step 1.
STEP 3 - Create a
SCAN listener for each VIP that was created in step 2.
STEP 4 - Change
the tnsnames.ora file. This entry will point SCAN to the single
DNS hostname created in step 1. Prior to the introduction of SCAN (11g r1
and earlier using TAF or intelligent load
balancing ), the tnsnames.ora file contained a list of hostnames,
one for each node in the cluster:
SCANDB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = myscan1.mydomain.com)(PORT = 1522))
(ADDRESS = (PROTOCOL = TCP)(HOST = myscan2.mydomain.com)(PORT = 1522))
(ADDRESS = (PROTOCOL = TCP)(HOST = myscan3.mydomain.com)(PORT = 1522))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = SCANDB)
)
)
STEP 5 - Set the remote_listener
and local_listener parameters: You want to set your remote_listener
parameter to point to a tnsnames.ora entry for SCAN as defined in step 4.
remote_listener=myscan.mydomain.com:1522
The SCAN listener for RAC
This single domain addressing is implemented via a
"scan listener" and the status can be checked with the standard
lsnrctl command, passing the SCAN listener name as an argument:
oracle> lsnrctl service
oracle> lsnrctl stat myscan_listener
LSNRCTL
for UNIX: Version 11.2.0.1.0 . .
Connecting to
(DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_MYSCAN1)))
STATUS of the LISTENER . . .
Server control commands for SCAN
According to Karen Reidford, there are several new server
control (srvctl) commands for SCAN:
New SRVCTL Command
|
What it does
|
srvctl config scan
|
Shows the current SCAN configuration
|
srvctl config scan_listener
|
Shows the existence and port numbers for the SCAN
listeners
|
srvctl add scan -n cluster01-scan
|
Adds new SCAN information for a cluster
|
srvctl remove scan -f
|
Removes SCAN information
|
srvctl add scan_listener
|
Adds a new SCAN listener for a cluster on the default
port of 1521
|
srvctl add scan_listener -p 65001 ## non default port
number ##
|
Adds a new SCAN listener on a different port
|
srvctl remove scan_listener
|
Removes the SCAN listener
|
srvctl modify scan -n cluster_scan
|
Modifies SCAN information (used when changing SCAN to DNS
after initially using /etc/hosts)
|
srvctl modify scan_listener -u
|
Modifies the SCAN listener information to match the new SCAN
VIP information from the modify scan command
|
6.How to install rac.Steps.
7 EVMD /
23: Which daemon is responsible for relocating
the VIP if needed?
24: What will happen if a node is thrown out
of the building (25th floor)?
28: What happens when instance is added on a
new node using DBCA.
29: What is the difference between Single
Instance and one node RAC.
30: What is the difference between Services of
a single instance and RAC?
32: How to change the ORACLE_HOME of
clusterware and RAC Database?
35: How to remove a CRS application with
Unknown state ?
38 new
features in 11grac for configuration of private interconnect?HAIP
41. cpu patch on rac steps?
42. upgrading rac environment?
43 How to add/remove node in RAC?
44. what are rolling patches and how to apply?
45. how to mount the rac standby database? and
how to enable the recovery process?
47. how to find out if any LUNS are corrupted on linux?
As an Oracle
DBA in a non-cluster environment, your responsibilities limited to manage,
troubleshoot and diagnose problems that are pertaining to the database technologies.
In contrast, you will have an additional responsibility of managing Clusterware
and troubleshooting its problems in a cluster environment. The purpose of this
article is to help you understanding the basics about Clusterware startup
sequence and troubleshoot most common Clusterware startup failures.
Additionally, this article also wills focus on some of the useful tools,
utilities that are handy identifying the root cause of Clusterware related
problems.
In my perspective and personal experience, the following is
some of the challenges most DBAs in their cluster environment confront:
- Node eviction
- Cluster becoming unhealthy
- Unable to start cluster and some of the Clusterware components
Clusterware startup sequence
It’s worthwhile understanding how things get started or
stopped while managing and troubleshooting a system. In this segment, we will
closely look at how an Oracle
Clusterware stack components are get started, and in which sequence they come
up on a node reboot or manual cluster startup. This understanding will greatly
help addressing most cluster stack common start-up failures and gives you a
glance where to start the investigation in case any cluster component doesn’t
start.
The diagram below depicts Oracle
Cluster stack (components) startup sequence at various levels:
Source: Expert Oracle
RAC 12c
The entire Oracle
Cluster stack and the services registered on the cluster automatically comes up
when a node reboots or if the cluster stack manually starts. The startup
process is segregated in five (05) levels, at each level, different processes
are got started in a sequence.
On node reboot/crash, the init process on the OS spawns
init.ohasd (as mentioned in the /etc/inittab file), which in turn commence Oracle
High Availability Service Daemon (ohasd). The ohasd daemon is then responsible
of starting off the other critical cluster daemon processes.
The new oraagent and oraclerootagent layers then brings up
Cluster Synchronization Daemon (cssd), Cluster Ready Services (crsd), Event
Manager Daemon (evmd) and other rest of Cluster stack in addition to ASM, RDBMS
instances and other resources on the cluster at various levels.
Cluster-wide cluster commands
With Oracle
11gR2, you can now start, stop and verify Cluster status of all nodes from a
single node. Pre Oracle
11gR2, you must login to individual nodes to start, stop and verify cluster
health status. Below are some of the cluster-wide cluster commands:
- $ ./crsctl check cluster –all
[verify cluster status on all nodes]
- $ ./crsctl stop cluster –all
[stop cluster on all nodes]
- $ ./crsctl start cluster –all
[start cluster on all nodes]
- $ ./crsctl check cluster –n
[verify the cluster status on a particular remote node]
Troubleshooting common cluster startup problems
Once you understand the startup sequence and how things get
started in Oracle
Cluster environment, it will easy for anyone to troubleshoot and solve most
common start-up failure problems. In this segment, we will explain how to
diagnose some of the common Cluster start-up problems.
Imagine your ‘crsctl check cluster/crs’ command and its
gives the following errors:
$GRID_HOME/bin/crsctl check cluster
CRS-4639: Could not contact Oracle High Availability Services
CRS-4124: Oracle High Availability Services
startup failed
CRS-4000: Command Check failed, or completed with errors
OR
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530:
Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot
communicate with Event Manager
We will start taking the issues of the components startup
failures in the same sequence they usually start. Let’s talk about ohasd
startup failures which would result in ‘CRS-4639/4124/4000’ errors. The
following are the main causes:
- Verify if the /etc/inittab file contains the entry to start the
ohasd process automatically.
- Ensure Cluster auto startup is configured using the ‘crsctl
config crs’ command. For any reasons it is not auto start configured,
enable the auto start and start the cluster manually.
- Refer alert.log and ohasd.log files under
$ORA_GRID_HOME/log/hosname location.
- Ensure the node has no issues accessing the OLR and OCR/Voting
Disks. This can be verified in the alert or ohasd log files.
In the event of Cluster Synchronization Service Daemon
process (cssd) start-up failures or reported unhealthy status, follow the
below guide lines to resolve the problem:
- Verify if the cssd.bin is active on the OS or not: ps –ef |grep
cssd.bin
- Review the alert log and ocssd.log files
- Ensure there is no issues with regards to Voting Disks
accessibility
- Also, check the network heart beat between the nodes
- Run crsctl stat res –t –init, and if the crsd process is
unhealthy, start it up manually
$
./crsctl start res ora.crsd –init
--------------------------------------------------------------------------------
NAME TARGET
STATE
SERVER
STATE_DETAILS
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.asm
1 ONLINE ONLINE
rac2
Started
ora.cluster_interconnect.haip
1 ONLINE
ONLINE
rac2
ora.crsd
1 ONLINE
OFFLINE
rac2
ora.cssd
1 ONLINE
ONLINE
rac2
ora.cssdmonitor
1 ONLINE
ONLINE
rac2
ora.ctssd
1 ONLINE
ONLINE
rac2
OBSERVER
ora.diskmon
1 ONLINE
ONLINE
rac2
ora.evmd
If you encounter Cluster Ready Services Daemon
(CRSD) start-up failures or reported unhealthy, you can perform the
following check list:
- Verify if the crsd.bin process is up on the OS: ps –ef |grep
crsd.bin
- Refer alert log and crsd logs to get useful information about
the nature of the problem
- Check the status of the resources using the above command, and
start it manually if the status/target is OFFLINE
- Ensure OCR disks are accessible to the node and there no OCR
corruption
If you couldn’t resolve the problem reviewing the
above guide lines, you might need to contact Oracle
support and provide all required information to investigate further on the
problem.
CRS logs and directory hierarchy
Each component of Grid Infrastructure (Clusterware)
maintains an individual log file and writes important events to the log file
under typical circumstances. The information written to the log will help DBAs
to understand the current state of the component, also assist troubleshooting
cluster critical problems. DBA should comprehend the importance of these log
files and able to understand the text to solve the problems. Each node in the
cluster maintains an individual log directory under
$GRID_HOME/log/ location for every cluster component, as shows
in the following screen shot:
Source: Expert Oracle
RAC 12c
The following are some of the most referred logs as part of
cluster maintenance and troubleshooting various Cluster related problems, such
as, Node eviction, Cluster stack heath, OCR/Voting disk related problems etc:
- alert_hostname.log
- crsd.log
- ocssd.log
- ohasd.log
alert_hostname.log Each
cluster node has its own alert log file and write important and useful
information about cluster startup, node eviction, any cluster component
start-up problems, OCR/Voting disk related information. It is therefore recommended
to refer the log file frequently to know the cluster status, in the event of
other node eviction, or wants to keep an eye on OCR/VD developments.
ocssd.log Yet another very
critical and important log file which needs your attention. Whenever cluster encounters
any serious snags with regards to Cluster Synchronization Service Daemon (CSSD)
process, this is the file that needs to refer to understand the nature of the
problem and to resolve the problem too. This is one of the busiest log files
that is writing continuously and maintained by the cluster automatically.
Manual maintenance on the file is not recommended, and once the file size
reaches to 50MB, Oracle
automatically archives the files and create a new log file. In the context,
total 10 archive log files are maintenance at any given point in time.
crsd.log Cluster Ready
Service Daemon (CRSD) process writes all important events to the file, such as,
cluster resources startup, stop, failure and CRSD health status. If you have
issues starting/stopping any cluster and non-cluster resources on the node,
refer this log file to diagnose the issue. This files also maintained by the Oracle
and remove the file is not recommended. Once the size of the file reaches to
10MB, it will be archived automatically and a new log file will be created.
There will be 10 archived copies of the file will be kept under any point of
time.
ohasd.log The log file is
accessed and managed by the new Oracle
High Availability Service Daemon (ohasd) process which was first introduced in Oracle
11gR2. If you encounter any issues running root.sh or rootupgrade.sh scripts,
refer to this log file to understand troubleshooting the problem. If you face
issues starting up the process, and if Oracle
Local Registry (OLR) has any corruption or inaccessibility issues, also refer
to this file. Like crsd and ocssd log files, this file also is maintained
automatically by Oracle
and archives the log file upon reaching 10MB size. Total of 10 archived log
files are maintained at any given point in time.
Debugging and Tracing CRS components
As we have learned that CRS maintains a good amount of log
files for various Cluster components which can be referred anytime to diagnose
critical cluster startup issues, node eviction and others events. If the
default debugging or logging information doesn’t provide sufficient feedback to
resolve any particular issues, you can go on and increase the debug/trace level
of a particular component or cluster resource to generate additional debugging
information to address the problem.
Fortunately, Oracle
let you adjust the default trace/debug levels of any cluster component or
resource dynamically. To list the default trace/debug settings of a component
or sub-component, login as root user and execute the following command from the
GRID_HOME:
- $ ./crsctl get log
css/crs/evm/all
To adjust/change the default trace level, use the
following example:
- $ ./crsctl set log crs
crsmain=4
- $ ./crsctl set log crs all-=3
[all components/sub-components of CRS set to level 3]
You will have to seek Oracle
support advice before you set or adjust any default settings. To disable the
trace/debug level, set the level to value 0. You can set the levels from 1 to
5. The more the value, the more information will be generated and you must
closely watch the log file growth and space on the filesystem to avoid any
space related issues.
You can also turn on trace through OS settings; use the
following OS specific command:
$
export SRVM_TRACE=true
Once the above is set on any UNIX OS system, trace/log
files are generated under $GRID_HOME/cv/log destination. Once you exit from the
terminal, tracing will end.
Oracle
Clusterware Troubleshooting – tools & utilities
One of the prime responsibilities of an Oracle
DBA is managing and troubleshooting the cluster system. In the context, the DBA
must aware of all the internal and external tools and utilities provided by Oracle
to maintain and diagnose cluster issues. The understanding and weighing the
pros and cons of each individual tool/utility is essential. You must have a
great knowledge and should choose the right tool/utility at the right moment;
else, you will not only waste the time to resolve the issue, instead, will have
a prolonged service interruption.
Let me zip through and explain you the benefits of some of the very important
and mostly used tools and utilities here.
- Cluster Verification Utility (CVU)
– is used to collect pre and post cluster installation configuration
details at various levels and various components. With 11gR2, it also
provides the ability to verify the cluster health. Look at some of the
useful commands below:
$
./cluvfy comp healthcheck –collect cluster –bestpractice –html
$ ./cluvfy comp
healthcheck –collect cluster|database
- Real Time RAC DB monitoring (oratop) – is an external Oracle
utility, currently available on Linux platform, which provides OS specific
top alike output where you can monitor RAC databases/single instance
databases in real time. The window provides statistics real-time, such as:
DB Top event, top Oracle
processes, blocking session information etc. You must download the
oratop.zip from support.oracle.com
and configure it.
- RAC configuration audit tool (RACcheck) – yet another Oracle
provided external tool developed by the RAC support team to perform audit
on various cluster configuration. You must download the tool
(raccheck.zip) from the support.oracle.com
and configure it on one of the nodes of cluster. The tool performs
cluster-wide configuration auditing at CRS,ASM, RDMS and generic database
parameters settings. This tool also can be used to assess the readiness of
the system for the upgrade. However, you need to keep upgrading the tool
to get the latest recommendations.
- Cluster Diagnostic Collection Tool (diagcollection.sh)– Since cluster manages so many log files, sometime it will be
time consuming and cumbersome to visit/refer all the logs to understand
the nature of the problem, or diagnose the issue. The diagcollection.sh
tool refers various cluster log files and gathers required information to
diagnose critical cluster problems. With this tool, you can gather the
stats/information at various levels: Cluster, RDBMS, Core analysis,
database etc. The tool encapsulates all file in a zip file and removes the
individual files. The following .zip files are collected as part of the
diagcollection run:
- ocrData_hostname_date.tar.gz
è contains ocrdump, ocrcheck etc
- coreData_hostname_date.tar.gz
à contains CRS core files
- osData_hostname_date.tar.gz
à OS logs
- ocrData_hostname_date.tar.gz
à OCR details
Example:
$
./GRID_HOME/bin/diagcollection.sh –collect –crs $GRID_HOME
$ ./diagcollection.sh –help
--collect
[--crs] For collecting crs diag information
[--adr] For collecting diag information for ADR; specify ADR location
[--chmos] For collecting Cluster Health Monitor (OS) data
[--all] Default.For collecting all diag information. <<<>>>
[--core] Unix only. Package core files with CRS data
[--afterdate] Unix only. Collects archives from the specified date.
[--aftertime] Supported with -adr option. Collects archives after the specified
[--beforetime] Supported with -adr option. Collects archives before the
specified
[--crshome] Argument that specifies the CRS Home location
[--incidenttime] Collects Cluster Health Monitor (OS) data from the specified
[--incidentduration] Collects Cluster Health Monitor (OS) data for the duration
NOTE:
1. You can also do the following
./diagcollection.pl --collect --crs --crshome
--clean cleans up the diagnosability
information gathered by this script
Above all, there is many other important and useful tools:
Cluster Health Monitoring (CHM) to diagnose node eviction issues, DB
Hanganalysis, OSWatcher, The Light on Monitor, ProWatcher etc are available for
your use under different circumstances.
In a nutshell, this paper
make you understand the Cluster startup sequence, how things get started on
node reboot and provides guide lines to solve most commonly faced Cluster
startup issues by analyzing the cluster logs, using appropriate tools/utilities
discussed.





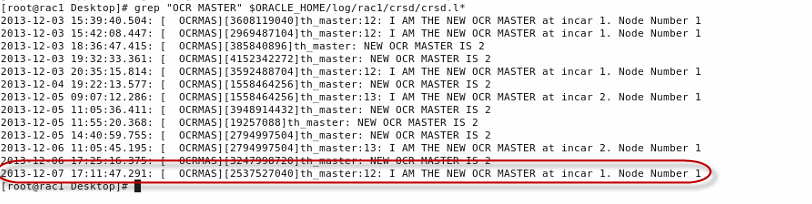{kind=link}
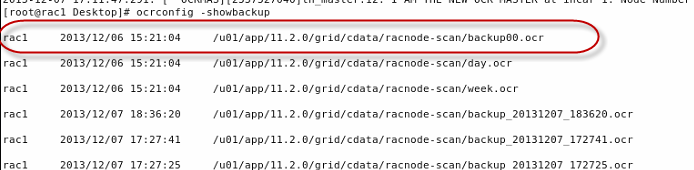{kind=link}
{kind=link}
{kind=link}